◆효율적 시장 가설과 해운시황 예측의 가능성
1980년대 해운산업 합리화, 1990년대 말의 IMF 위기에 따른 해운자산의 헐가(歇價) 매각, 2008년 글로벌 금융위기와 이어진 10여 년의 해운불황을 연이어 경험한 우리 해운업계에서는 정확한 해운시황 예측 서비스를 필요로 하고 있음. 덧붙여 해운원가 이하의 운임이 지속되더라도 등락의 변곡점만 알 수 있으면, 고점에 화물계약을 하고, 저점에 선박계약을 하면 수익을 거둘 수 있다는 사실은 이러한 해운시황 예측 서비스의 니즈(needs)를 더욱 크게 하고 있음.
그러나 특정 자산(asset)의 가격을 정확히 예측하는 것은 결코 쉬운 문제가 아님. 예를 들어, 금융시장에서는 주가와 같은 금융자산의 가격에는 알려진 모든 정보가 반영되어 있기 때문에 가격 예측에 기초하여 초과 수익을 지속적으로 얻기가 불가능하다고 알려져 있음. 이러한 경험을 반영한 이론을 효율적 시장 가설(Efficient Market Hypothesis)이라고 하고, 학계에서는 이 가설의 검증과 변칙(變則, anomaly)의 설명에 큰 노력을 기울여 왔음. 이 논의를 해운시장에 적용하면, 운송서비스의 가격(운임), 선박의 가격(선가), 미래 운송서비스의 가격(FFA 평가치) 등의 예측에 상당한 어려움이 있을 것임을 유추할 수 있음.
이 같은 어려움에도 불구하고, 객관적인 자료(data)에 기반한 여러 가지 방법의 해운시황 예측이 가능함. 먼저, 1985년 BIFFEX를 시작으로 해서 발전되어 온 벌크(건화물, 탱커) 운임의 선물거래의 하나인 FFA(Forward Freight Agreement)의 평가치가 해당 현물운임의 미래 가격을 예측하는데 유용하게 활용될 수 있음. 이러한 FFA 평가치의 미래 운임의 예측기능을 가격발견기능(price discovery function)이라고 부름. 그러나 이렇게 FFA 정보를 이용한 운임 예측은 평균적으로 성공적이지만, 구체적인 사례별로는 정확히 예측할 수 없다는 것이 알려져 있음.
두 번째 데이터에 기반한 해운시황 예측 방법은 시계열 모형 또는 인공지능 모형을 이용하는 것을 검토해 볼 수 있음. 앞서 언급한 효율적 시장 가설에 따르면 예측이 불가능한 자산의 가격은 임의 보행(random walk)을 하는 것으로 알려져 있음. 임의 보행은 흔히 만취하여 이리저리 돌아다니는 걸음걸이를 통계학적으로 모형화한 것임. 즉 우리가 만취한 사람의 미래 위치를 예측할 수 없듯이, 자산 가격 또한 예측이 곤란하다는 것임. 그러나 우리가 관심을 가지는 해운시황 지표의 움직임이 순수한 임의 보행만 따르는지, 아니면 예측 가능한 부분을 포함하고 있는 지를 분석할 필요는 남게 됨.
◆현물 운임과 FFA 평가치
현물 운임과 FFA 평가치는 모두 해상운송 서비스의 가격이라는 공통점이 있음. 그러나 현물 운임은 실제 선박과 화물의 거래를 기반으로 하는데 비해, FFA는 실제 선박과 화물이 없이 거래된다는 큰 차이점이 있음. 즉 현물 운임의 거래비용(transaction cost, 거래가 이루어지기 위해 필요한 다양한 실제적 비용. 그러나 거래가격에는 반영되지 않음)은 크고, FFA의 거래비용은 거의 없음.
KMI의 분석에 따르면, FFA는 거래비용이 거의 없어 금융자산의 가격과 유사하게 임의 보행을 따르면서 효율적 시장 가설을 지지하는 것으로 나타남. 그러나 현물 운임은 거래비용이 수반되기 때문에 임의 보행 요소를 포함하면서 동시에 예측 가능한 부분을 가지는 것으로 분석됨. 즉 현물 운임은 시계열 분석을 통해 일정 부분 예측을 할 수 있는 것으로 판단됨.
◆예측 사례
아래 표는 KMI가 수요, 공급, 운임의 과거 데이터에 기반해 선종별로 해운시황의 방향을 예측한 사례의 결과를 보여주고 있음. 예측이 실제 의사결정 환경과 동일하게 직전 년도 말에 입수 가능한 자료에 기반했다는 점에서 전체 30가지 경우 중 22 경우에 방향을 맞추었다는 점에서 고무적이라고 평가됨.
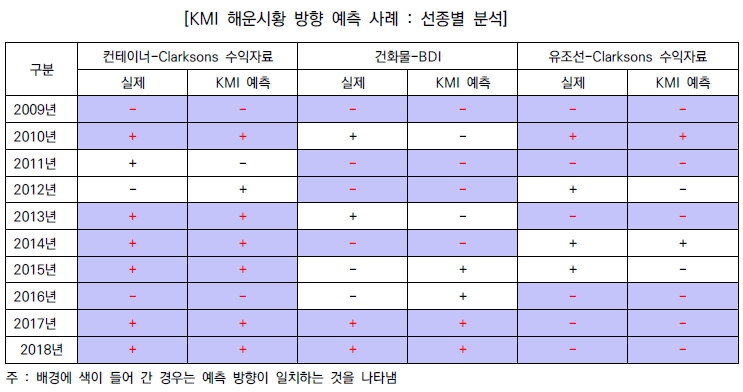
이러한 부분적 예측 성공 사례는 앞서 언급한 해운시장의 동태적 특성이 반영된 것임. 예측 방향이 맞는 경우는 운임자료가 가지는 예측 가능 부분이 실현된 것이며, 맞지 않는 경우는 임의 보행하는 운임의 성격이 상대적으로 크게 작용한 것으로 이해됨. 즉 예측이 성공한 경우는 수급 변수 및 자신의 과거 운임 값이 미래로 이어지는 부분에서 예측 가능한 방법으로 과거의 행태를 반복한 데 따른 것임.
◆KMI의 역할
산업계 전체를 대상으로 지식․정보를 제공하는 공공 연구기관의 경우에는 이와 같은 예측 모형과 방법론을 기업 종사자들에게 제공할 수 있음. 나아가 입수 가능한 산업의 데이터에 기반해 예측 서비스 또한 제시할 수 있음. 그러나 연구기관의 경우에는 상업적 거래주체가 아니기 때문에 본질적으로 가지게 되는 자료 입수의 제약 또한 존재함. 즉 선사, 중개업체 등과 달리 연구기관은 현재의 시장에서 공유되는 민감한 상업적 정보에는 접근하기가 어려운 부분이 있음. 즉 민간기업의 데이터 조건이 연구기관의 조건 보다 우위에 있다는 것임. 따라서 KMI와 같은 공공 연구기관은 위와 같은 방법론을 업계에 제공하여 업계 스스로가 객관적 방법론을 활용해 비즈니스에서 경쟁우위를 점할 수 있도록 지원할 수 있을 것임. 즉 이 같은 방법론 연구와 업계 보급이 KMI가 앞으로 수행할 역할 중 하나일 것임.
나아가 현대 사회는 4차 산업혁명으로 불리는 데이터 혁명을 겪으면서 다양한 종류의 빅데이터(Big Data)가 등장하고 있음. 앞의 예측은 전통적 자료인 Clarksons이 제공하는 데이터를 활용한 것인데, 이와 다른 빅데이터를 사용하면 더욱 정확한 시장 예측이 가능할 것으로 기대됨. KMI의 해운빅데이터연구센터는 이 같은 데이터 활용 방법론 연구와 이의 업계 보급에 최선을 다할 계획임. 올해 1월 29일(수)에 진행할 “KMI 해운기업 예측 역량 강화 세미나”는 이 같은 배경에서 추진되므로, 업계 종사자의 많은 참여를 기대함.
